Künstliche Intelligenzen sind nicht objektiv. Sie sind nicht mit neutralen Daten trainiert worden und produzieren auch keine neutralen Ergebnisse.
–
rund um die Uhr
Ausstellung
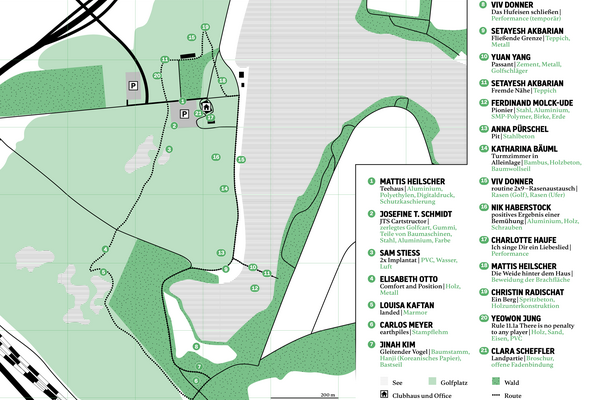
Feldarbeit – Ausstellung der Klasse Bildhauerei/Materialität und Raum
Künstliche Intelligenzen sind nicht objektiv. Sie sind nicht mit neutralen Daten trainiert worden und produzieren auch keine neutralen Ergebnisse.
KI sind hauptsächlich mit Daten aus der westlichen Welt trainiert, die bestimmte westlich geprägte gesellschaftliche Stereotypen enthalten. Diese Stereotypen betreffen das Aussehen von Menschen, deren Rolle in der Familie oder bei der Arbeit, ihre Hautfarbe, Religion, ihr Gender oder ihre sexuelle Orientierung. Je nach Modell variieren die Vorurteile, da Daten und Labeling variieren. Labeling beschreibt die Benennung, Beschreibung und Kategorisierung von Daten wie beispielsweise Bildern. Dies ist abhängig von Personen, die diesen Prozess durchführen oder ihn überwachen. Eine Verdeutlichung davon ist der Stable Diffusion Bias Explorer (Link) Nutzer*innen können sehen, welche Vorurteile in den Modellen stecken und sie miteinander vergleichen.
Überall, wo eine KI mit durch Menschen kategorisierte und mit von Menschen erzeugten Daten trainiert wird, übernimmt sie die persönlichen und gesellschaftlichen Vorstellungen und Realitäten. Dies beginnt bereits bei der Verfügbarkeit von Daten: Vorurteile im Machine Learning sind nicht nur technologische Probleme. Wer überhaupt Zugang zu Dienstleistungen hat, beeinflusst die Zusammensetzung der Datensätze. Es gibt zum Beispiel erhebliche Unterschiede im Zugang zu Gesundheitsversorgung zwischen sozialen Gruppen. Diejenigen, die am meisten Zugang haben, profitieren auch am meisten von der Anwendung maschineller Lerntechnologien, da sie in den Trainingsdaten der Algorithmen am besten repräsentiert sind. Dieses datenbasierte Vorurteil ist eine quantitative Verzerrung. Quantitative Verzerrungen können auftreten, wenn ein Datensatz unausgewogen ist, beispielsweise durch eine unzureichende Repräsentation von älteren Menschen, ethnischen Minderheiten oder Frauen. Qualitative Verzerrungen dagegen entstehen, wenn schlecht gekennzeichnete Bilder zu diskriminierenden Ergebnissen führen. Dies entsteht durch kognitive Verzerrungen, also durch die subjektive Wahrnehmung Einzelner bei der Kennzeichnung von Daten. Solange Menschen kognitive Verzerrungen haben prägen sie die Daten und die Generierungen.
Debiasing Prompting Tipps
Eigene Vorurteile in Prompts erkennen:
Prompts können eigene Vorurteile erkennen oder abschwächen, wenn sie folgende oder ähnliche Befehle beinhalten:
Quellen
https://medium.com/@laranguyen/debiasing-machine-learning-94cc32d3f2cc
https://learnprompting.org/docs/reliability/debiasing
https://github.com/oxai/debias-vision-lang