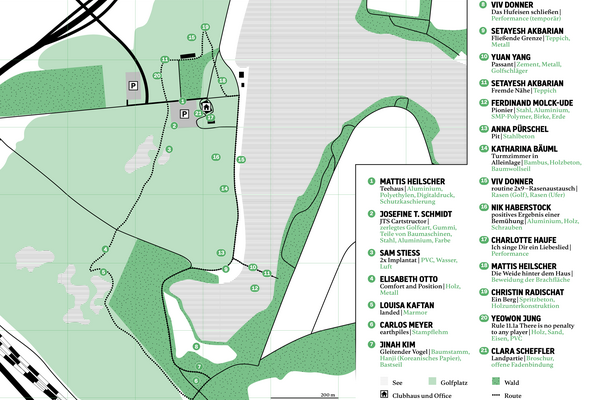
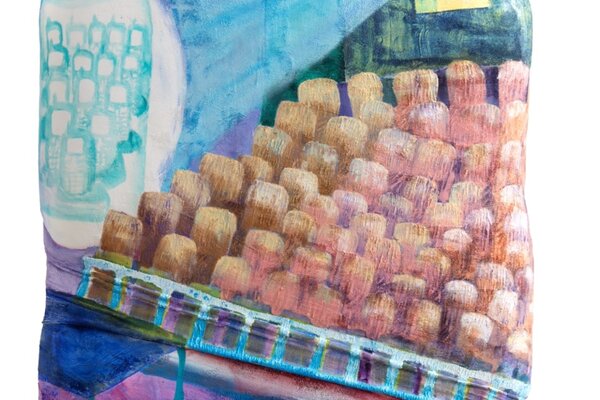Bilder mit Hilfe Künstlicher Intelligenz zu beschreiben und darin Objekte und Situationen zu erkennen, war für Forscher*innen lange eine große Herausforderung. Schließlich gelang dies mit Algorithmen des maschinellen Lernens. Mit dem Erfolg entstand die Idee, den Prozess umzukehren: Ist es möglich, realistische Bilder aus einer Textbeschreibung zu erzeugen? Die Installation Verboscope machte diesen Ansatz zur generativen Synthese von Bildern in Form einer Ausstellungsinstallation bereits frühzeitig erfahrbar und – bereits vor der inzwischen selbstverständlichen Verfügbarkeit von Bildgebenden KI-Systemen – für ein breites Publikum zugänglich.
Über einen Chat steht Verboscope mit den Nutzer*innen im Dialog. Aus den Bildanweisungen im Chat erstellt das System Bildwelten die durch weitere Eingaben iterativ beeinflusst und geformt werden können. Mit fortschreitender Nutzung wächst ein Korpus von Bildern aus Situationen, Orten und Objekten, die so zuvor noch nicht existierten.
In der aktuellen KI-Forschung werden hierfür zwei neuronale Netze miteinander kombiniert. Das eine erzeugt Bilder ohne Kenntnis des Inhalts, das andere wurde mit Milliarden von Bild-Text-Paaren aus Internetquellen trainiert. Dadurch enthält es eine umfangreiche Sammlung von visuellem Wissen, mit dem es die Ähnlichkeit eines Bildes mit einer gegebenen Textbeschreibung bewertet. Der Prozess führt das generative Netz zu einem gewünschten Bild. Diese Technik macht das Schaffen, Kombinieren und Bearbeiten von Bildern leicht zugänglich.